"Uber ML Platform"으로 보는 머신러닝 파이프라인의 데이터 흐름과 처리 과정
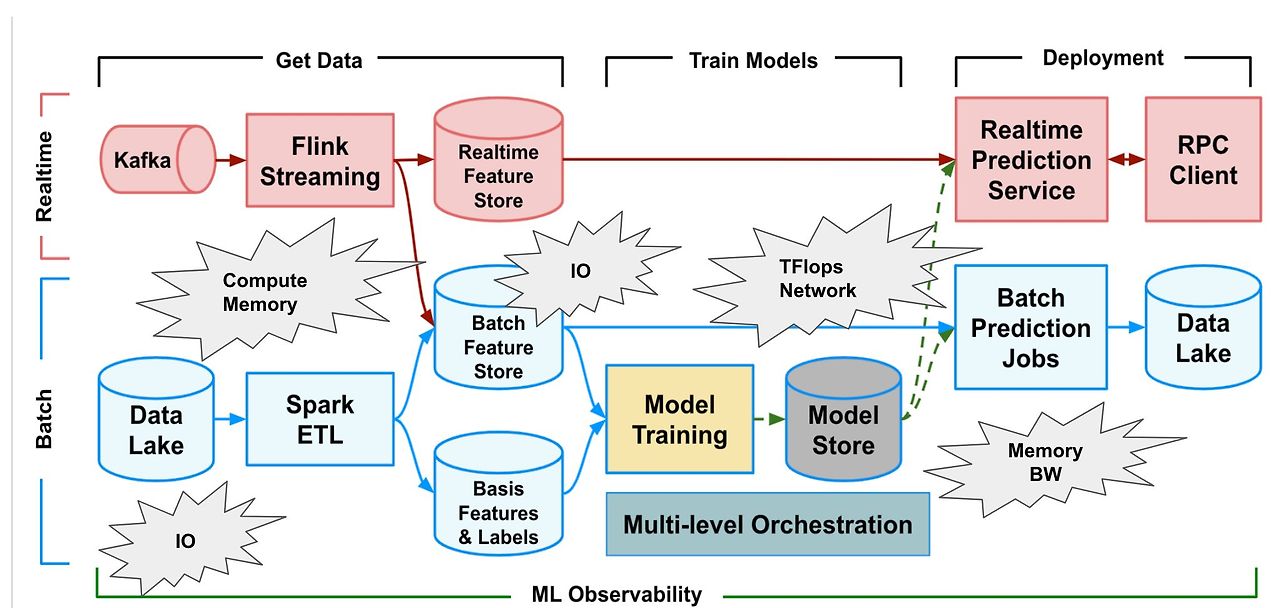
머신러닝 파이프라인의 데이터 흐름과 처리 과정
Uber ML Platform 다이어그램을 통해 실시간 데이터와 배치 데이터가 각각 어떻게 처리되고, 모델 학습 및 배포 과정에서 어떻게 사용되는지 알아보자.
1. 데이터 획득(Get Data):
- Kafka: 실시간 데이터 스트리밍 소스로부터 데이터를 수집한다.
- Data Lake: 대규모 배치 데이터(비실시간 데이터)를 저장하는 저장소이다.
2. 데이터 처리(Data Processing):
- Flink Streaming: Kafka에서 데이터가 수집된 후 처리되는 곳이다. 실시간 데이터 스트리밍 처리를 담당하며, 처리된 데이터는 Realtime Feature Store에 저장된다.
- Spark ETL: 배치 데이터를 처리하여 Batch Feature Store에 저장한다.
- Compute Memory와 IO는 데이터 처리에서 중요한 자원으로 메모리와 입출력 처리 속도에 영향을 미친다.
3. 모델 학습(Train Models):
- Model Training: 배치 데이터에서 Feature Store를 사용해 학습을 수행한다.
- Model Store: 학습된 모델을 저장하는 곳이다. 저장된 모델은 배치 예측 작업과 실시간 예측 서비스에 사용된다.
4. 배포(Deployment):
- Realtime Prediction Service: 실시간으로 예측을 수행하여 RPC Client에게 결과를 제공한다.
- Batch Prediction Jobs: 배치 데이터에 대한 예측 작업을 수행하고, 결과를 Data Lake에 저장한다.
5. ML 모니터링(ML Observability):
- Model Training이 될 때마다 Model들이 저장되는데, 저장되는 과정에서 모델에 대한 모니터링이 이루어진다.
- Multi-level Orchestration이 전체 파이프라인의 오케스트레이션과 모니터링을 담당한다.
배치 데이터와 배치 예측 작업
배치 데이터 (Batch Data)
배치 데이터는 한꺼번에 수집되고 처리되는 데이터 세트를 의미한다. 이 데이터는 실시간으로 발생하는 것이 아니라 일정 기간 동안 수집된 후, 한 번에 처리된다.
배치 데이터 처리는 하루 동안 웹사이트에서 발생한 모든 트랜잭션 데이터를 모아서 하루가 끝난 후 한 번에 처리하는 것으로 이해할 수 있다.
배치 데이터의 특징:
- 대규모 데이터: 배치 데이터는 대량의 데이터로 이루어져 있으며, 한 번에 처리되기 때문에 대규모의 데이터를 효율적으로 관리할 수 있다.
- 주기적 처리: 데이터가 수집된 후 정해진 주기(예: 하루, 일주일, 한 달)에 따라 처리된다.
- 지연 허용: 실시간 처리가 필요 없고, 약간의 처리 지연이 허용된다.
배치 예측 작업 (Batch Prediction Jobs)
배치 예측 작업은 배치 데이터에 대해 예측 모델을 적용하여 예측 결과를 생성하는 프로세스이다. 예측 모델은 사전에 학습된 머신러닝 모델이며, 배치 데이터에 적용되어 대량의 데이터를 한 번에 처리하고 결과를 도출한다.
배치 예측 작업의 특징:
- 대규모 처리: 배치 데이터 전체에 대해 예측을 수행하기 때문에, 보통 대규모 데이터를 한 번에 처리한다.
- 비실시간 처리: 배치 예측은 실시간으로 결과를 요구하지 않기 때문에, 처리 시간이 조금 걸리더라도 상관없다. 이는 대개 비즈니스 인텔리전스나 분석 보고서를 생성하기 위한 작업에 사용된다.
- 예측 결과 저장: 배치 예측 작업이 완료되면 그 결과는 Data Lake나 다른 데이터베이스에 저장되어, 이후에 분석되거나 활용된다.
예시
배치 작업의 예시로는 온라인 쇼핑몰에서 고객의 구매 기록을 바탕으로 다음 달에 어떤 제품이 많이 팔릴지를 예측하는 작업이 있다.
이러한 작업은 매일 또는 매주 한 번씩 수행될 수 있으며, 결과는 마케팅 전략 수립에 활용될 수 있다.
실시간 데이터와 실시간 예측 작업
실시간 데이터 (Real-time Data)
실시간 데이터는 데이터를 생성하는 이벤트가 발생하는 즉시 수집되고 처리되는 데이터이다.
센서 데이터, 웹사이트 클릭스트림 데이터, 소셜 미디어에서의 실시간 피드 등이 실시간 데이터의 예이다.
실시간 데이터의 특징:
- 지속적인 데이터 스트림: 데이터는 지속적으로 생성되고, 실시간으로 처리된다.
- 즉시성: 데이터가 발생하는 즉시 처리되어야 하며, 지연이 거의 허용되지 않는다.
- 주로 작은 단위: 실시간 데이터는 이벤트 단위로 작게 들어오지만, 이 이벤트가 매우 빈번하게 발생한다.
실시간 예측 작업 (Real-time Prediction Jobs)
실시간 예측 작업은 실시간 데이터에 대해 예측 모델을 적용하여 즉각적인 예측 결과를 제공하는 프로세스이다. 이 작업을 통해 데이터가 발생하자마자 예측 모델을 통해 실시간으로 결과를 도출하고, 그 결과를 즉시 활용할 수 있다.
실시간 예측 작업의 특징:
- 빠른 응답 시간: 실시간 예측 작업은 매우 빠른 응답 시간이 요구된다. 예측 결과는 데이터를 수신한 즉시 제공되어야 한다.
- 연속적인 처리: 실시간 데이터 스트림에 대해 지속적으로 예측을 수행한다.
- 저지연: 예측 작업은 매우 낮은 지연 시간으로 처리되어야 하며, 이는 사용자가 즉각적으로 반응할 수 있도록 한다.
예시
실시간 데이터 예시
- 금융 거래 모니터링: 주식 거래소에서 발생하는 수천 건의 거래 데이터를 실시간으로 수집하여, 가격 변동, 거래량 등을 분석한다.
- 스마트 홈 시스템: 스마트 홈의 센서 데이터(예: 온도, 조명, 움직임 센서 등)를 실시간으로 모니터링하고, 이를 기반으로 환경을 자동으로 조정한다.
실시간 예측 작업 예시
- 실시간 사기 탐지: 신용카드 거래 시스템에서 실시간으로 거래 데이터를 분석하여, 사기 거래 여부를 즉시 예측하고, 이상 거래가 발견되면 즉시 차단하거나 경고를 발송한다.
- 실시간 광고 추천: 사용자가 웹사이트를 탐색할 때, 사용자의 현재 클릭 스트림 데이터를 실시간으로 분석하여, 즉각적으로 개인화된 광고를 추천한다.
- 자율 주행 자동차: 자율 주행 자동차는 주변 환경(도로 상황, 장애물 등)에 대한 센서 데이터를 실시간으로 처리하여, 차량의 이동 경로를 실시간으로 결정한다.